It might sound like something straight out of a Philip K. Dick novel, but your robots txt file is key to helping Google and other search engines find your most valuable content.

Think of it as a set of instructions or directives for search engine crawlers (sometimes called crawl bots, spiders or robots).
Not sure what a crawler is? Don't worry. They’re not half as technical (or alarming) as they sound. Basically, search companies like Google build complex computer programmes that race around the internet – cataloguing content and working out what it’s about so that search engines can serve relevant results to user queries like “how to change a tyre” or “what is SEO?”.
When one of these crawlers reaches your website, it starts combing through your content. Most crawl bots follow hyperlinks from one page to the next, indexing everything as they go, but other, more sophisticated crawlers like the Baiduspider or Googlebot will look at your sitemap first – building a detailed picture of your site that allows them to ferret out any orphan pages that can’t be accessed from the main part of your site.
Think of them as the archetypical nosy librarian, snooping in every nook and cranny to build up a comprehensive list of the content on your site.
But most crawl bots will listen to specific instructions – as long as they’re given in a recognisable format.
Your robots txt file provides those instructions, telling crawl bots which pages to ignore and which parts of your site it’s ok to index.
It's fairly technical stuff, but it's not as complicated as some people make it out to be, and we're keen to pull back the curtain on a lot of so-called "SEO black magic" so we've decided to pull together an in-depth guide to this file – explaining what it is, why we use it, and how you can check, make or edit your own.
Why Do We Use This File?
If you want to get really geeky, the syntax used in the file was developed by a man called Martijn Koster, widely credited with creating the world’s first search engine (Aliweb).
According to an internet legend, Martijn created his robots exclusion protocol after a colleague built a bad crawl bot that inadvertently crashed his website by visiting every page hundreds of times.
Preventing this kind of accident is actually one of the main reasons we still use these files today. Crawling a website strains its servers and can cause it to crash, so most search companies set a ‘crawl budget’ for their bots. That is, a maximum number of pages a bot will crawl before it quits the site and moves onto the next domain on its list.
This isn’t a problem for small sites. But if you’re running a site with thousands of web pages, there’s a good chance that incoming crawl bots will miss some of your pages unless you use a file to tell them where to focus.
Imagine you’re running a B2C clothing website like missguided.co.uk. You have a few hundred category pages that you want Google to index, and several thousand paginated pages that are basically duplicates of the initial category pages (page 23 of “outdoor coats” is a great example).
You don’t want Google to waste its limited crawl budget looking at 456 identical pages of dress shoes when there’s a good chance it’d then miss your blog or a couple of popular category pages so you could tell it to ignore paginated pages entirely.
You could also tell it to ignore pages with a number in the url, but we’ll cover that sort of thing in more detail later on.

Where Can I Find My Robots.txt File?
If your site already has a robots file, you should be able to find it by typing your domain name and adding /robots.txt at the end (eg. https://www.redevolution.com/robots.txt).
These files are normally kept here because crawl bots are only programmed to look for exclusion protocols at the root domain. It’s industry best practice to keep them there, and placing them in a subfolder means that they’ll probably be missed or ignored by most major web crawlers.
If you can’t find your file, you can try looking for it in your server files. The way you'll go about this is very platform and server dependant so if you're not sure how to access your FTP cPanel or download files from your server, get in touch with your web management team. They’ll be able to steer you in the right direction.
What Should Be In My File?
This depends on the type and complexity of the site you’re running. Small sites with sensible architecture (read: well organised content) will probably have a relatively straightforward file.
Ours is a good example. Looking at the screen-grab below, you can see that we’ve blocked access to our cache, image files and admin pages because we don’t want those areas of the site to waste crawl budget indexing those pages.
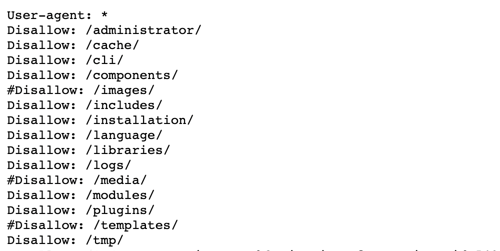
We’ve also advised crawl bots to ignore plugin libraries, logs and other miscellaneous sections of the site that we’re not trying to rank but all of the rest of our content is fully accessible because our website’s quite small, and we want crawlers to look at most of our pages.
But for a site like missguided.co.uk, more rules are needed to stop crawl bots indexing search results pages, and other, miscellaneous sections of the site.

Note that Missguided have also disallowed access to their checkout and wish list pages because there could be thousands of these at any given time, and there’s no chance that Googlebot or any other crawl bot would get through them in one session.
If you're unsure about what’s in your robots.txt file or think it might be blocking access to an important part of your site, talk to an SEO specialist. They’ll be able to tell you whether your file’s been set up correctly and help you troubleshoot any major problems.
A file that blocks access to the wrong parts of your website can stop Google and other search engines from indexing your content – killing your search rankings and strangling your organic traffic.
Conversely, a file that doesn’t cordon off irrelevant parts of your website could encourage search bots to waste their budget on content that won’t rank for important keywords, killing your search rankings and (you guessed it) strangling your organic traffic.
It’s a delicate balancing act, and one you need to get right so if you’ve got questions about your file, make sure you chat to an expert!

Creating Or Modifying A Robots File
If you can’t find your file (or it’s not getting the job done) it might be time to get your hands dirty and make your own. Tread carefully here: You need to have a thorough understanding of the robots exclusion protocol and a sound working knowledge of your website’s structure.
If you're a busy marketer and you'd rather not delve into the technical intricacies of exclusion protocols, give us a ring. We've been helping clients with technical SEO for over 18 years now and we're more than happy to take care of the tricky bits.
But if you’re willing to take your time and are good at following instructions, there’s no reason you shouldn’t have a go at improving your file.
Let’s start with the syntax. There are four terms you’ll need to know:
User-agent
User-agent: is used to call out the web crawler you want to instruct. You can give crawl instructions on a per-crawler basis (eg. User-agent: Googlebot Disallow: /example-subfolder/) or give instructions to all web crawlers by typing User-agent:*
Disallow
Disallow: is the command used to tell a bot not to crawl a particular URL or subset of URLs
Allow
Allow: is the command used to tell crawl bots they’re allowed to crawl the specified URLs. It’s mainly used when you want to block access to a subfolder, but allow indexing of a specific page within that folder but it’s only used by Googlebot and most crawl bots will ignore it.
Crawl-delay
Crawl-delay: is the command that tells crawlers to wait before loading and crawling a page - and allows you to specify a delay time in seconds. Unfortunately, Googlebot routinely ignores these commands so they’re not terribly useful.
And now that we’ve got the syntax down, it’s just a case of gluing all the parts together. Open a plain text editor, and specify the user agent. Use the wildcard or * if you want to address all of them, or search the following list
Once you’ve specified the user agent you want to instruct, start listing the URLs you want it to avoid. Generally speaking, it’s best to keep one url per line, but you can do some fairly advanced things with wild cards and query strings here (more on that below).
Once you’ve finished writing your robots.txt file, ask your dev or web team to upload it to your root domain and you’re good to go.
If you want to double-check that everything’s working correctly, you can test your robots.txt file using Google’s robots.txt checker.
Things To Include In Your File
This is part recommendation, part advanced class for quick learners who want to write their robots.txt file. It’s probably best to ignore this section if you’re not 100% comfortable with the above syntax.
That said, you can do some dead clever things with your robots.txt file. Especially useful for people running big or complex sites that use up a lot of crawl budget. For example, you can use robots.txt to:
Stop bots from crawling any URL with a specific parameter, like ?size = (a common parameter in auto-generated on-site search results) by typing
User-agent: *
Disallow: /*?size
Stop bots from crawling any URL with a specific parameter EXCEPT specific exceptions that you do want Google to index.
User-agent: *
Disallow: /*?size
Allow: /*?size=18
Prevent bots from crawling comment feeds in WordPress (particularly useful for those of us with comments enabled on our blogs)
User-agent: *
Disallow: /comments/feed/
Stop crawl bots from crawling any URL in a common child directory by typing:
User-agent: *
Disallow: /*/child/
Block crawl bots from crawling any URL that ends with “.pdf” – Note, if there are parameters appended to the URL by typing:
User-agent: *
Disallow: /*.pdf$

Getting Help With Your Robots.txt File
Head reeling? Don’t worry. It’s not at all uncommon. We live and breathe technical SEO but most people’s eyes glaze over once you start talking about user agents and crawl spiders.
If you’d rather hand over to someone who knows their way around a robots.txt file, we’re happy to help. We’ve been looking after our clients’ SEO for well over 18 years now and we’re always happy to lend a hand.

